What to Expect in the blog?
Discover the power of Uber’s Michelangelo ML platform, supporting over 10 million predictions per second, with a robust feature store and scalable end-to-end ML workflows.
Introduction
As machine learning matures, organizations with complex operations face the challenge of building robust, scalable ML platforms. Uber’s Michelangelo is an excellent example of how to do this successfully. Handling more than 10 million real-time predictions per second, Michelangelo embodies the future of scalable machine learning with end-to-end capabilities that address everything from feature engineering to deployment.
In this post, I’ll break down how Michelangelo works and why it has become a crucial component of Uber’s success. Drawing from my experience with machine learning and product development, I’ll also explore what we can learn from Uber’s approach to handling data at scale.
1. The Power of End-to-End ML Workflows
Michelangelo provides Uber’s teams with an end-to-end ML workflow, allowing them to manage data, build and train models, deploy those models into production, and monitor their performance—all in one platform. This streamlined workflow supports a variety of ML tasks, including:
- Classification for demand prediction, fraud detection, and more.
- Regression models for fare estimation and surge pricing.
- Time-series forecasting used for forecasting traffic or delivery times.
With these capabilities, Michelangelo empowers data scientists and engineers to quickly develop models that meet Uber’s needs. This efficiency in model development not only saves time but also enables Uber to remain agile in a competitive market.
2. Scalability: Meeting the Demand of 10 Million Predictions per Second
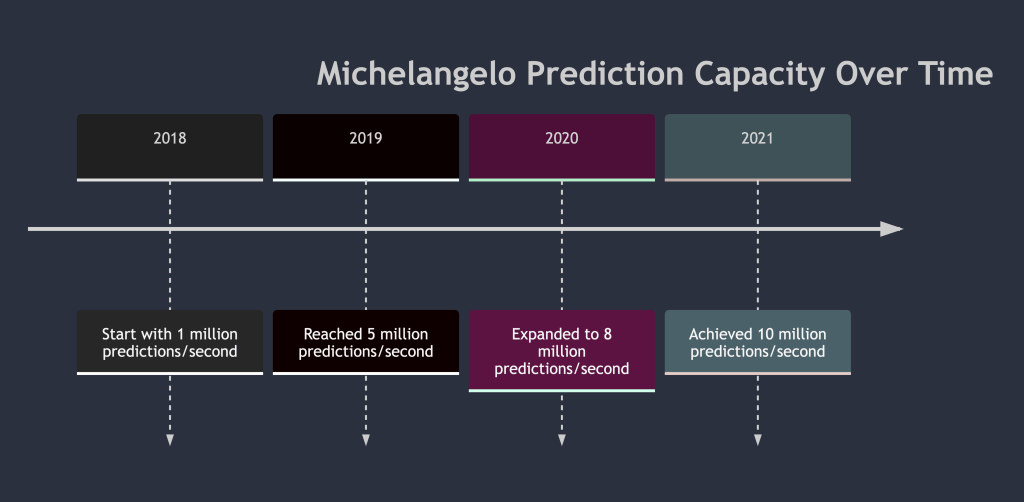
One of Michelangelo’s most impressive features is its scalability. The platform can support up to 10 million predictions per second at peak times and handles around 20,000 model training jobs monthly. These figures highlight how Michelangelo enables Uber to:
- Meet demand across services such as UberEATS, which requires real-time predictions for delivery estimates.
- Provide reliable fare predictions and optimize routing, both of which rely on scalable ML infrastructure.
Michelangelo achieves this scale through a mix of open-source technologies (like TensorFlow and Spark) and proprietary infrastructure optimized for Uber’s unique requirements. By combining these elements, Uber has crafted a platform that supports massive throughput without compromising performance.

3. Michelangelo’s Feature Store: An Asset for Model Consistency
One of Michelangelo’s unique components is its feature store. This centralized repository allows teams across Uber to share and reuse features, leading to several key advantages:
- Consistency Across Models: Reusing features ensures that models are consistent, which is particularly important when training models that interact with each other.
- Reduction in Redundancy: By storing common features like location or time of day, Michelangelo reduces the need for redundant feature engineering.
- Enhanced Model Accuracy: The availability of high-quality, tested features improves model performance across use cases.
Uber’s use of a feature store also points to a broader trend in machine learning: centralized data management. As organizations grow, establishing a feature store is essential for maintaining consistency and quality across ML models.

4. The Practical Impact: Numbers that Matter
To understand Michelangelo’s impact, let’s look at some numbers:
- 10 million predictions per second at peak times, supporting everything from rider demand predictions to UberEATS delivery estimates.
- 400+ active ML projects across Uber’s global operations.
- 20,000+ model training jobs every month, representing the continuous refinement and optimization of Uber’s ML models.
These metrics demonstrate how Michelangelo isn’t just a tool; it’s a foundation for Uber’s data-driven services. By meeting high prediction demands, Michelangelo allows Uber to scale efficiently while providing reliable, data-driven experiences for users worldwide.
5. Key Takeaways from Michelangelo’s Success
Michelangelo offers a valuable model for organizations looking to build scalable, end-to-end ML platforms. Here are the key lessons we can learn from Uber’s approach:
- Build for Scalability from Day One: As Uber demonstrates, anticipating the need for large-scale model training and deployment is critical for any business that depends on real-time data.
- Centralize Feature Management: Michelangelo’s feature store shows that centralizing feature engineering can lead to more accurate models and more efficient development cycles.
- Optimize for Real-Time Performance: Michelangelo’s ability to handle millions of predictions per second underscores the importance of optimizing for real-time applications, especially for consumer-focused products.
