Module 1: Introduction to Data Quality
1.1 Understanding Data Quality Fundamentals
Data quality refers to the state of qualitative or quantitative data that determines its fitness to serve its purpose in a given context. High-quality data must possess these key characteristics:
- Accuracy
- Correctness of values
- Alignment with real-world facts
- Example: Customer address matches their actual location
- Completeness
- All required data elements are present
- No missing critical values
- Example: All mandatory fields in a customer profile are filled
- Consistency
- Data is uniform across all systems
- No contradictions in related data
- Example: Same customer details across CRM and billing systems
- Timeliness
- Data is available when needed
- Updates occur within expected timeframes
- Example: Real-time inventory updates
- Validity
- Data follows defined formats and rules
- Adheres to business constraints
- Example: Email addresses following correct format
1.2 Impact of Poor Data Quality
Business Impact Analysis

Case Study: The $20 Million Data Quality Mistake
A major retail chain discovered that 25% of their product data contained errors:
- Incorrect pricing in system: $12.99 instead of $21.99
- Impact: $20 million in lost revenue
- Root cause: Manual data entry errors and lack of validation
- Solution implemented: Automated data quality checks
1.3 Data Quality in Machine Learning
Impact on ML Models
# Example: Impact of data quality on model accuracy
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
def demonstrate_data_quality_impact():
# Sample dataset with good quality
good_quality_data = pd.DataFrame({
'feature1': [1, 2, 3, 4, 5] * 20,
'feature2': [2, 4, 6, 8, 10] * 20,
'target': [0, 0, 1, 1, 1] * 20
})
# Introduce data quality issues
poor_quality_data = good_quality_data.copy()
poor_quality_data.loc[0:25, 'feature1'] = None # Missing values
poor_quality_data.loc[26:50, 'feature2'] *= 1000 # Outliers
# Compare model performance
def train_and_evaluate(data):
X = data[['feature1', 'feature2']].fillna(-999)
y = data['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = LogisticRegression()
model.fit(X_train, y_train)
return accuracy_score(y_test, model.predict(X_test))
return {
'good_quality_accuracy': train_and_evaluate(good_quality_data),
'poor_quality_accuracy': train_and_evaluate(poor_quality_data)
}
1.4 Practical Exercises to you
Exercise 1: Data Quality Assessment
Objective: Evaluate data quality in a sample dataset
-- Sample dataset for analysis
CREATE TABLE customer_data (
customer_id INT,
email VARCHAR(255),
phone VARCHAR(20),
registration_date DATE,
last_purchase_date DATE
);
-- Data quality checks
SELECT
'Missing Email' as issue_type,
COUNT(*) as issue_count
FROM customer_data
WHERE email IS NULL
UNION ALL
SELECT
'Invalid Phone',
COUNT(*)
FROM customer_data
WHERE phone NOT REGEXP '^[0-9]{10}$'
UNION ALL
SELECT
'Future Dates',
COUNT(*)
FROM customer_data
WHERE registration_date > CURRENT_DATE
OR last_purchase_date > CURRENT_DATE;
Module 2: Overview of Uber’s Data Quality Platform (UDQ)
2.1 Introduction to UDQ
2.1.1 Evolution of Data Quality at Uber
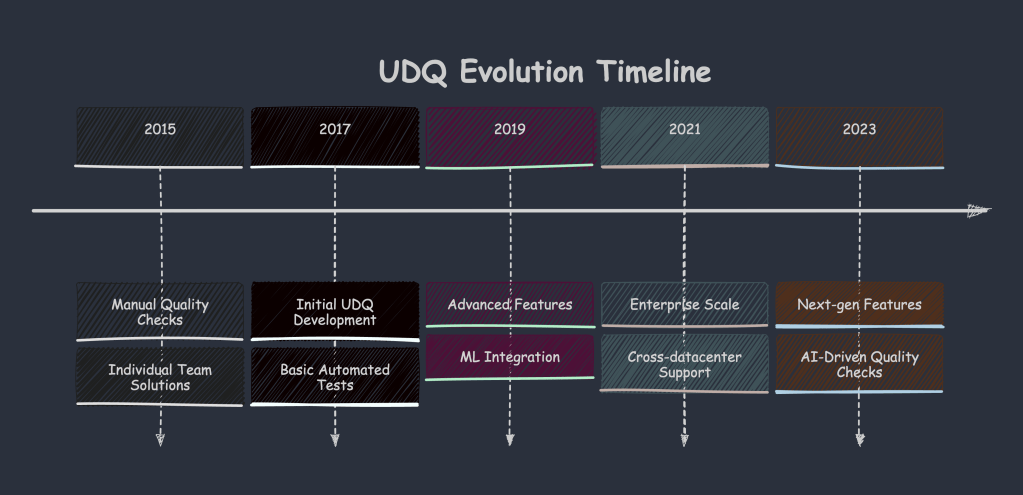
2.1.2 Why UDQ?
Key Drivers
- Scale Requirements
- Billions of trips
- Millions of users
- Petabytes of data
- Business Critical Nature
- Real-time decisions
- Financial implications
- Safety considerations
- Complexity Management
- Multiple data sources
- Various data formats
- Different velocity streams
2.2 Core Features of UDQ
2.2.1 Automated Testing Framework
# Example of UDQ-style test definition
class UDQTest:
def __init__(self, table_name: str, test_type: str):
self.table_name = table_name
self.test_type = test_type
self.conditions = []
def add_condition(self, column: str, condition: str, threshold: float):
self.conditions.append({
'column': column,
'condition': condition,
'threshold': threshold
})
def generate_test_query(self):
base_query = f"SELECT COUNT(*) as violation_count FROM {self.table_name}"
where_conditions = []
for cond in self.conditions:
where_conditions.append(
f"{cond['column']} {cond['condition']}"
)
if where_conditions:
base_query += " WHERE " + " AND ".join(where_conditions)
return base_query
# Usage example
ride_quality_test = UDQTest('ride_events', 'data_quality')
ride_quality_test.add_condition('pickup_time', 'IS NOT NULL', 1.0)
ride_quality_test.add_condition('fare_amount', '> 0', 0.99)
2.2.2 Real-time Monitoring
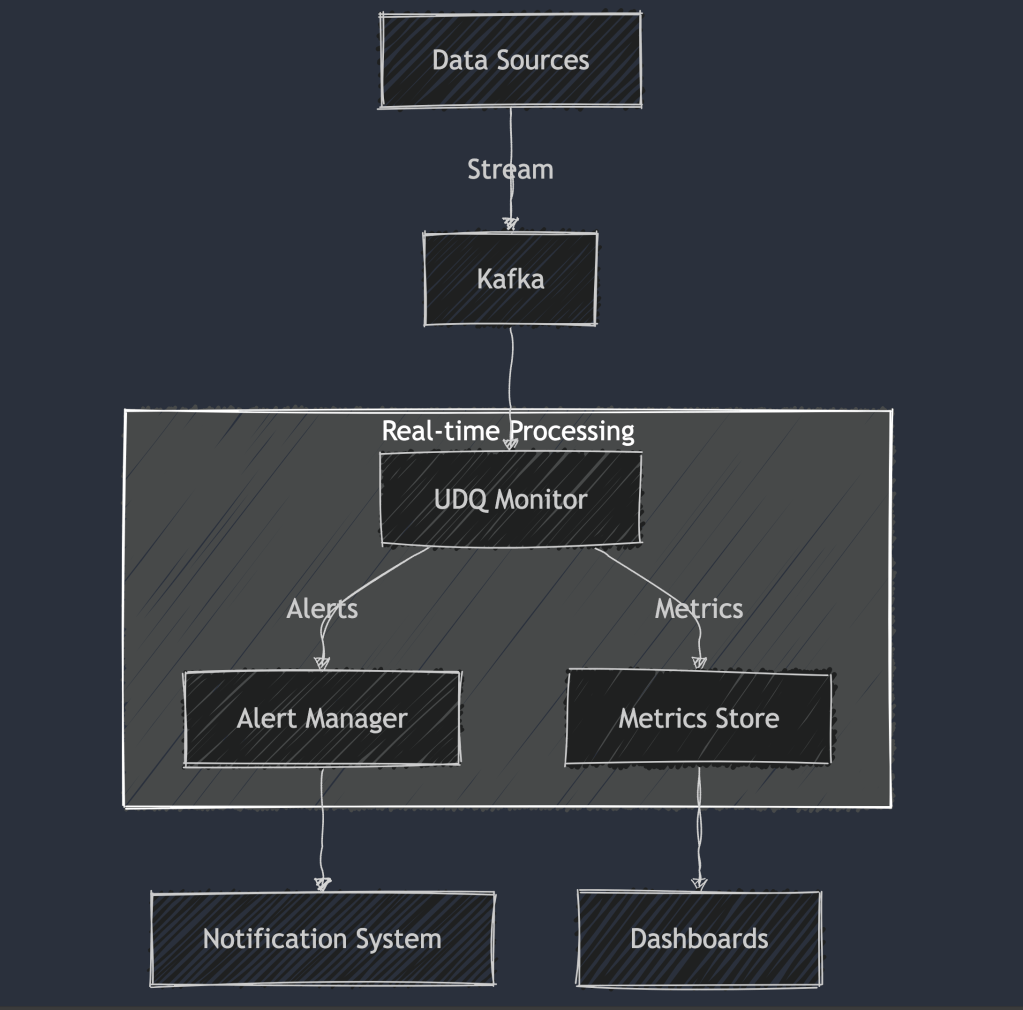
2.2.3 Scalable Architecture
# Example of UDQ's scalable test execution
from typing import List, Dict
import asyncio
class UDQExecutor:
def __init__(self, max_concurrent_tests: int = 10):
self.max_concurrent_tests = max_concurrent_tests
self.test_queue = asyncio.Queue()
self.results = []
async def add_test(self, test: Dict):
await self.test_queue.put(test)
async def execute_tests(self):
workers = [
self.worker(f"worker-{i}")
for i in range(self.max_concurrent_tests)
]
await asyncio.gather(*workers)
return self.results
async def worker(self, worker_id: str):
while True:
try:
test = await self.test_queue.get_nowait()
result = await self.run_single_test(test)
self.results.append(result)
self.test_queue.task_done()
except asyncio.QueueEmpty:
break
async def run_single_test(self, test: Dict):
# Simulate test execution
await asyncio.sleep(1)
return {
'test_id': test['id'],
'status': 'success',
'execution_time': 1.0
}
2.3 Benefits of UDQ
2.3.1 Operational Benefits
- Reduced Manual Effort
- Automated test creation
- Scheduled execution
- Auto-remediation
- Improved Coverage
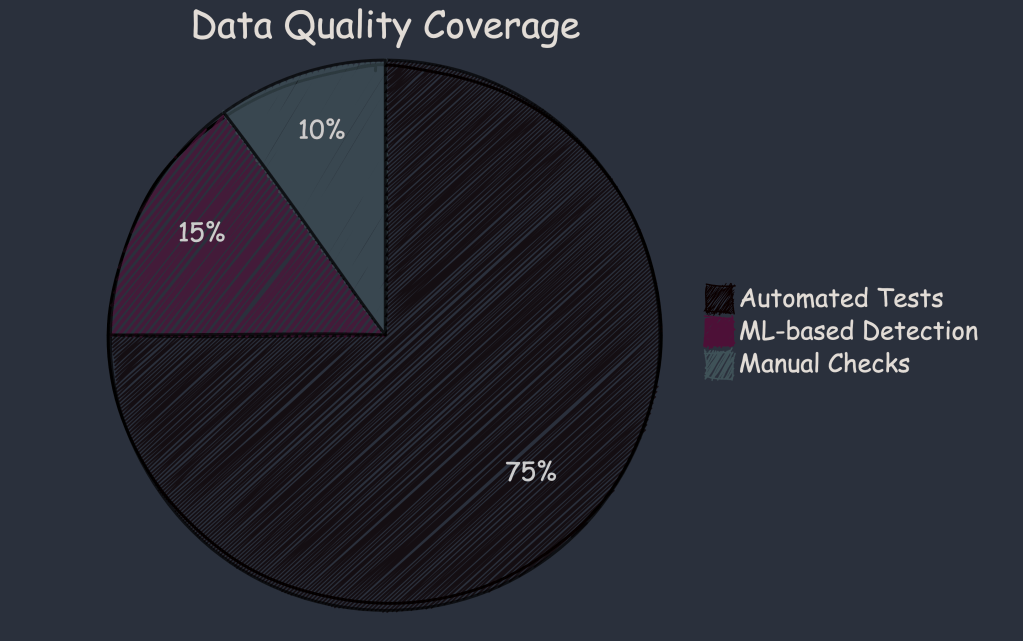
- Faster Issue Detection
- Real-time monitoring
- Proactive alerts
- Trend analysis
2.3.2 Business Benefits
- Cost Savings
def calculate_cost_savings(
manual_check_hours: float,
hourly_rate: float,
automated_maintenance_hours: float
) -> dict:
manual_cost = manual_check_hours * hourly_rate * 52 # Annual
automated_cost = automated_maintenance_hours * hourly_rate * 52
savings = manual_cost - automated_cost
return {
'manual_annual_cost': manual_cost,
'automated_annual_cost': automated_cost,
'annual_savings': savings,
'savings_percentage': (savings / manual_cost) * 100
}
# Example usage
savings = calculate_cost_savings(
manual_check_hours=40, # Weekly hours
hourly_rate=100, # Cost per hour
automated_maintenance_hours=5
)
- Improved Decision Making
- Enhanced Customer Experience
2.4 Practical Exercises for you
Exercise 1: Setting Up a Basic UDQ Test
# Implementation exercise
def implement_basic_udq_test():
"""
Create a basic UDQ test that checks for:
1. Data freshness (last update within 1 hour)
2. Completeness (no null values in critical columns)
3. Validity (values within expected ranges)
"""
pass
# Test specifications
test_specs = {
'table': 'ride_events',
'freshness': {
'column': 'event_timestamp',
'max_delay_minutes': 60
},
'completeness': [
'rider_id',
'driver_id',
'pickup_location'
],
'validity': {
'fare_amount': {'min': 0, 'max': 1000},
'distance': {'min': 0, 'max': 100}
}
}
Exercise 2: Analyzing UDQ Results
-- Sample query for analyzing test results
WITH test_results AS (
SELECT
test_id,
execution_time,
status,
DATE_TRUNC('hour', created_at) as hour
FROM udq_test_executions
WHERE created_at >= CURRENT_DATE - INTERVAL '7 days'
)
SELECT
hour,
COUNT(*) as total_tests,
SUM(CASE WHEN status = 'success' THEN 1 ELSE 0 END) as passed_tests,
AVG(execution_time) as avg_execution_time
FROM test_results
GROUP BY hour
ORDER BY hour;
Module 3: Challenges in Maintaining Data Quality
3.1 Understanding Data Quality Challenges
3.1.1 Scale and Complexity Challenges
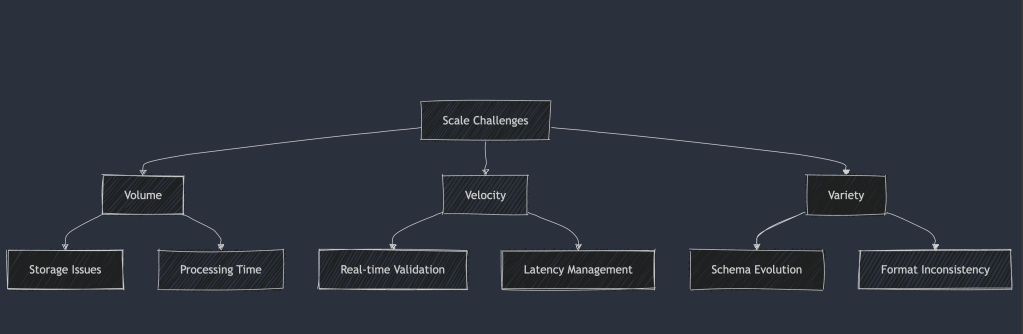
Example: Handling High-Volume Data Validation
class DataValidator:
def __init__(self, batch_size: int = 10000):
self.batch_size = batch_size
self.validation_results = []
async def validate_large_dataset(self, data_iterator):
"""
Validates large datasets in batches
"""
total_records = 0
invalid_records = 0
async for batch in self._get_batches(data_iterator):
batch_results = await self._validate_batch(batch)
total_records += len(batch)
invalid_records += len(batch_results['invalid'])
if batch_results['invalid']:
self.validation_results.extend(batch_results['invalid'])
return {
'total_records': total_records,
'invalid_records': invalid_records,
'error_rate': invalid_records / total_records if total_records > 0 else 0
}
async def _get_batches(self, iterator):
batch = []
async for record in iterator:
batch.append(record)
if len(batch) >= self.batch_size:
yield batch
batch = []
if batch:
yield batch
async def _validate_batch(self, batch):
invalid_records = []
for record in batch:
if not self._is_valid_record(record):
invalid_records.append({
'record': record,
'errors': self._get_validation_errors(record)
})
return {
'invalid': invalid_records
}
3.1.2 Standardization Challenges
Common Standardization Issues
- Data Format Inconsistencies
class DataStandardizer:
def __init__(self):
self.format_rules = {
'phone': r'^\+?1?\d{10}$',
'email': r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$',
'date': r'^\d{4}-\d{2}-\d{2}$'
}
def standardize_phone(self, phone: str) -> str:
"""Standardize phone number format"""
# Remove all non-numeric characters
cleaned = ''.join(filter(str.isdigit, phone))
# Format to standard format
if len(cleaned) == 10:
return f"+1{cleaned}"
elif len(cleaned) == 11 and cleaned.startswith('1'):
return f"+{cleaned}"
raise ValueError(f"Invalid phone number: {phone}")
def standardize_date(self, date_str: str) -> str:
"""Standardize date format to YYYY-MM-DD"""
try:
# Handle multiple input formats
for fmt in ('%Y-%m-%d', '%m/%d/%Y', '%d-%m-%Y'):
try:
parsed_date = datetime.strptime(date_str, fmt)
return parsed_date.strftime('%Y-%m-%d')
except ValueError:
continue
raise ValueError(f"Invalid date format: {date_str}")
except Exception as e:
raise ValueError(f"Date standardization failed: {str(e)}")
- Schema Differences
-- Example of schema standardization view
CREATE OR REPLACE VIEW standardized_customer_data AS
SELECT
CASE
WHEN source = 'system_a' THEN customer_id::VARCHAR
WHEN source = 'system_b' THEN cust_number::VARCHAR
ELSE id::VARCHAR
END as standardized_customer_id,
CASE
WHEN source = 'system_a' THEN CONCAT(first_name, ' ', last_name)
WHEN source = 'system_b' THEN customer_name
ELSE full_name
END as standardized_customer_name,
-- Standardize date formats
CASE
WHEN source = 'system_a' THEN
TO_DATE(creation_date, 'YYYY-MM-DD')
ELSE registration_date
END as standardized_registration_date
FROM
(
SELECT 'system_a' as source, * FROM system_a_customers
UNION ALL
SELECT 'system_b' as source, * FROM system_b_customers
UNION ALL
SELECT 'system_c' as source, * FROM system_c_customers
) combined_data;
3.1.3 Performance Challenges
Monitoring System Performance
class PerformanceMonitor:
def __init__(self):
self.metrics = {}
self.alerts = []
async def monitor_validation_performance(self, validation_func):
"""Decorator to monitor validation performance"""
async def wrapper(*args, **kwargs):
start_time = time.time()
result = await validation_func(*args, **kwargs)
execution_time = time.time() - start_time
# Record metrics
self.metrics[validation_func.__name__] = {
'execution_time': execution_time,
'timestamp': datetime.now(),
'result_size': len(result) if isinstance(result, (list, dict)) else 1
}
# Check for performance issues
if execution_time > 5.0: # threshold in seconds
self.alerts.append({
'type': 'performance_warning',
'function': validation_func.__name__,
'execution_time': execution_time,
'timestamp': datetime.now()
})
return result
return wrapper
3.2 Case Studies
3.2.1 Real-world Data Quality Challenge
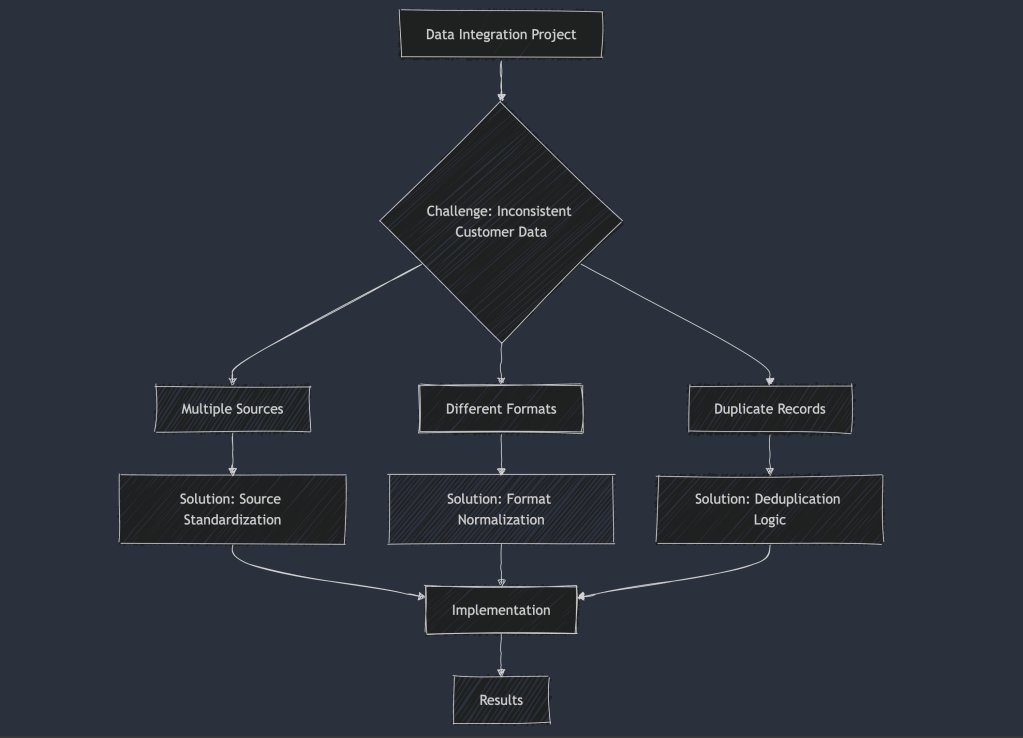
3.2.2 Implementation Example
class CustomerDataCleaner:
def __init__(self):
self.deduplication_rules = {
'exact_match': ['email', 'phone'],
'fuzzy_match': ['name', 'address']
}
def clean_customer_record(self, record: dict) -> dict:
"""Clean and standardize customer record"""
cleaned = {}
# Standardize name
if 'name' in record:
cleaned['name'] = self._standardize_name(record['name'])
# Standardize contact information
if 'email' in record:
cleaned['email'] = record['email'].lower().strip()
if 'phone' in record:
cleaned['phone'] = self._standardize_phone(record['phone'])
# Standardize address
if 'address' in record:
cleaned['address'] = self._standardize_address(record['address'])
return cleaned
def find_duplicates(self, records: List[dict]) -> List[List[dict]]:
"""Find duplicate customer records"""
duplicates = []
exact_matches = defaultdict(list)
# First pass: exact matches
for record in records:
key = self._create_match_key(record)
exact_matches[key].append(record)
# Second pass: fuzzy matches
for records in exact_matches.values():
if len(records) > 1:
duplicates.append(records)
return duplicates
3.3 Practical Exercises for you
Exercise 1: Implementing Data Quality Monitors
# Task: Implement a data quality monitoring system
class DataQualityMonitor:
"""
TODO: Implement monitoring system that:
1. Tracks data quality metrics over time
2. Generates alerts for anomalies
3. Provides performance statistics
"""
pass
# Test cases
test_cases = [
{
'scenario': 'Missing Values',
'input_data': [
{'id': 1, 'name': None, 'email': 'test@example.com'},
{'id': 2, 'name': 'John', 'email': None}
],
'expected_alerts': ['missing_name', 'missing_email']
},
# Add more test cases...
]
Module 4: UDQ’s Approach to Data Quality Standardization
Introduction
Data quality standardization is crucial for maintaining consistency and reliability across large-scale data systems. Uber’s Data Quality (UDQ) framework provides a systematic approach to identifying, categorizing, and addressing data quality issues.
Common Data Quality Issues
- Data inconsistencies across systems
- Missing or incomplete records
- Outdated information
- Duplicate entries
- Schema violations
- Data format inconsistencies
Test Categories
1. Freshness Tests
- Definition: Ensures data is up-to-date and available within expected timeframes
- Key Metrics:
- Time since last update
- Update frequency compliance
- Latency in data pipelines
- Implementation Examples:
Example freshness check
SELECT COUNT(*) FROM table
WHERE update_timestamp >
(CURRENT_TIMESTAMP - INTERVAL '24 hours')
2. Completeness Tests
- Definition: Verifies that all required data is present and properly populated
- Aspects to Check:
- NULL value detection
- Required field validation
- Record count verification
- Coverage across time periods
- Implementation Examples:
Example completeness check
SELECT
COUNT(*) total_records
, SUM(CASE
WHEN critical_field IS NULL THEN 1
ELSE 0
END) missing_values
FROM table
3. Duplicate Tests
- Definition: Identifies and flags duplicate records based on business rules
- Types of Duplicates:
- Exact duplicates
- Fuzzy duplicates
- Business logic duplicates
- Detection Methods:
- Hash-based comparison
- Field-by-field comparison
- Custom business rules
4. Cross-datacenter Consistency Tests
- Definition: Ensures data consistency across different data centers and regions
- Key Considerations:
- Replication lag
- Schema consistency
- Data synchronization
- Conflict resolution
- Monitoring Aspects:
- Record counts
- Checksum validations
- Version tracking
5. Semantic Checks
- Definition: Validates business rules and logical relationships in the data
- Types of Checks:
- Value range validation
- Relationship verification
- Business logic compliance
- Trend analysis
- Implementation Examples:
Example semantic check
SELECT
COUNT(*)
FROM orders
WHERE total_amount < 0
OR quantity <= 0
Module 5: Components of UDQ Architecture
Test Execution Engine
- Purpose: Orchestrates the execution of data quality tests
- Features:
- Scheduling capabilities
- Resource management
- Parallel execution
- Error handling
- Implementation Considerations:
- Scalability
- Performance optimization
- Resource allocation
- Failure recovery
Test Generator
- Purpose: Creates and manages test cases
- Capabilities:
- Template-based test generation
- Custom test definition
- Test versioning
- Parameter management
- Key Features:
- Reusable test templates
- Dynamic parameter handling
- Test dependency management
Alert Generator
- Purpose: Manages the notification system for quality issues
- Components:
- Threshold configuration
- Notification routing
- Alert prioritization
- Alert aggregation
- Alert Types:
- Critical alerts
- Warning alerts
- Information alerts
Incident Manager
- Purpose: Handles the lifecycle of data quality incidents
- Features:
- Incident tracking
- Root cause analysis
- Resolution workflow
- Documentation
- Process Flow:
- Incident detection
- Classification
- Assignment
- Investigation
- Resolution
- Documentation
Metric Reporter
- Purpose: Generates and maintains quality metrics
- Metrics Types:
- Test coverage
- Issue resolution time
- Quality trends
- System performance
- Reporting Features:
- Real-time dashboards
- Historical analysis
- Trend visualization
- Custom reports
Consumption Tools
- Purpose: Provides interfaces for accessing and utilizing quality data
- Types of Tools:
- Web interfaces
- API access
- Integration points
- Reporting tools
Module 6: Future Directions in Data Quality Management
Backtesting Techniques
- Current Approaches:
- Historical data validation
- Pattern recognition
- Anomaly detection
- Future Developments:
- Machine learning integration
- Automated pattern discovery
- Predictive quality management
Advanced Anomaly Detection
- Emerging Techniques:
- Deep learning models
- Time series analysis
- Contextual anomaly detection
- Implementation Strategies:
- Model selection
- Feature engineering
- Training procedures
- Validation methods
Dimension/Column Level Tests
- Enhanced Capabilities:
- Granular testing
- Custom validation rules
- Automated test generation
- Implementation Considerations:
- Performance impact
- Storage requirements
- Maintenance overhead
Emerging Trends
- AI-Driven Quality Management:
- Automated test generation
- Intelligent alerting
- Predictive maintenance
- Real-time Quality Monitoring:
- Stream processing
- Immediate detection
- Automated correction
- Enhanced Visualization:
- Interactive dashboards
- 3D data visualization
- AR/VR integration
- Integration with Modern Data Stack:
- Cloud-native solutions
- Microservices architecture
- Containerization
